讯飞医疗MaaS平台-模型精调平台
开始使用
平台简介
训练平台快速入门——功能速览
讯飞医疗MaaS平台-模型广场
讯飞医疗MaaS平台-数据管理
讯飞医疗MaaS平台-模型精调
讯飞医疗MaaS平台-批量推理
讯飞医疗MaaS平台-模型评估
讯飞医疗Maas平台-模型蒸馏
讯飞医疗MaaS平台-模型仓库
讯飞医疗MaaS平台-用量监控
模型能力
模型列表
模型能力
API参考
实践指南
功能详情
模型广场
数据管理
模型精调
批量推理
模型评估
模型蒸馏
模型仓库
用量监控
常见问题
相关协议
本文档使用 MrDoc 发布
-
+
首页
模型评估
模型评估是通过预设的打分指标,对模型回答的准确性、安全性、逻辑性等方面进行量化分析的过程,旨在衡量模型是否满足实际应用需求。 在讯飞医疗MaaS模型训练平台中,模型评估的过程更加侧重于各模型在医疗方面的能力评估。 ## 模型评估数据集来源 您可以在创建评估任务时直接选择数据集。 在页面中,您可以直接点击选择批量推理结果,即使用您在模型推理后得到的数据,进行模型评估。 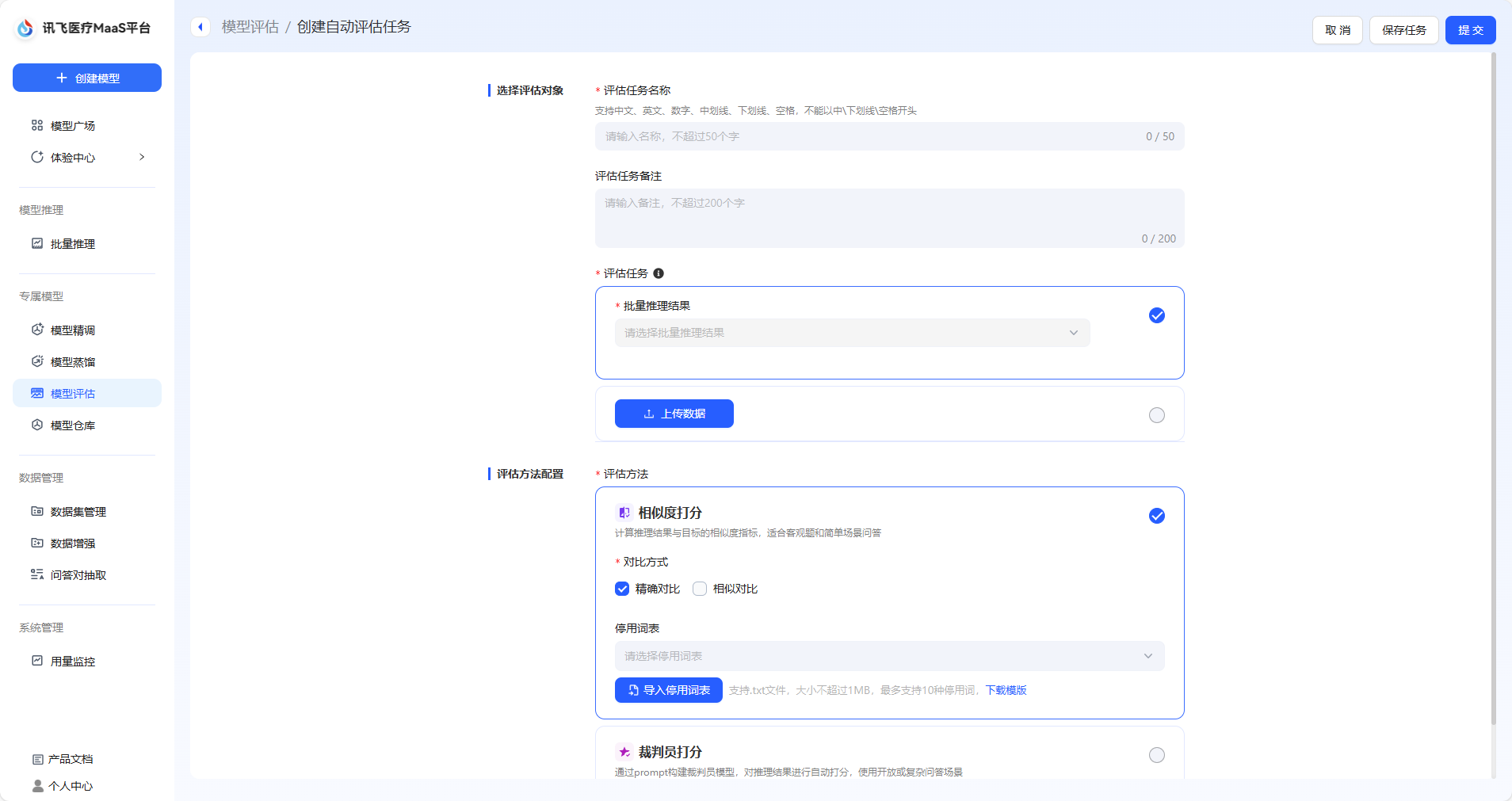 或者,您可以点击上传数据按钮,从而选择评测数据集。 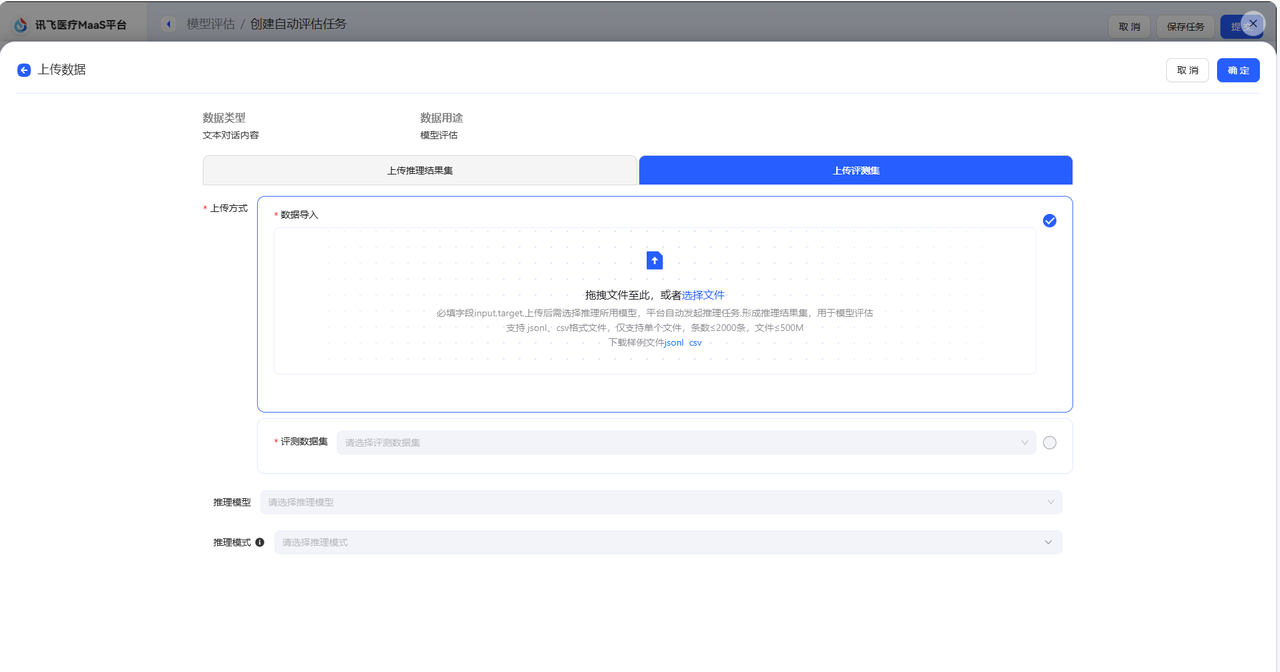 在该页面中,有两种上传方式。 一种是上传推理结果集,该方式支持您上传通过其他方式处理得到的评测集,该数据集必须是csv格式,且包含三个字段:input(用户输入),target(期望结果),model_1_output(模型推理结果),支持您下载样例文件模板。该种方式不可选择模型进行推理。 另一种是上传评测集,具体介绍如下。 |来源|操作|是否支持选择模型进行推理|描述| |:--:|:---:|:-----:|:----| 预置数据集|点击下拉框,选择预置的数据集,预置数据集支持多选|是|预置医疗评测集:包含知识问答、信息提取、意图理解、指令遵循、住院内涵质控、门诊病历质控、诊断推荐、专科辅诊、导医导诊、文书生成和医学考试11个维度的评测集,满足用户多种模型评估需求,为您提供全面的医疗模型应用评估服务。 本地上传|点击本地上传,选择数据集。|是|您所上传的数据集,支持jsonl和csv格式,且必须包含两种字段,input(用户输入),target(标注结果)。 数据集管理中已创建完成的评测集|点击下拉框,选择相应评测集。|是|支持预先在数据集管理页面中创建评测集。进入数据集创建页面后,数据集类型选择评测集即可实现评测集的创建。您可以在数据集管理页面实现对该数据集的管理。 标注平台一键上传|点击下拉框,选择相应评测集。| 若仅包含用户输入和标注结果的数据集:**是**<br>若包含用户输入、标注结果、机器结果的数据集:**否**|目前系统支持将在讯飞医疗MaaS-标注平台中标注后的数据集一键上传至训练平台,该评测集可以在数据集管理页面中看到,数据集来源显示为:标注平台上传。 ## 评估方式选择 在模型评估的配置中,根据用户选择的评测集的不同,平台支持不同的打分方式 | 评测集 | 评估方式 | 描述 | 打分指标 | | ------------ | :---------------------- | ------------------------------------------------------------ | ------------------------------------------------------------ | | 预置评测集 | 综合评分&各能力维度评分 | 用户选择内置的数据集对模型评估时,平台支持采用综合打分制和维度打分制对模型进行评估。 | **综合评分**来自模型在全部能力维度上评分的均分。**能力维度评分**来自各能力维度下所有数据集评测后得分的均分。平台预置的医疗评测集,已经根据内容匹配到对应的能力维度。 | | 非预置评测集 | 相似度打分 | 相似度打分是一种用于衡量预测结果与真实结果之间相似程度的量化指标。该打分方式通过将模型的输出与实际数据进行比较,最终使用ROUGE值来衡量模型评估的结果。 | **ROUGE**:在自然语言处理(NLP)任务中,ROUGE是一种常用的摘要评估指标,分值越大越好,ROUGE分值越大,表示生成的文本与参考文本的相似度越高。 | | | 裁判员打分 | 裁判员打分通过prompt构建裁判员模型,对推理结果进行自动打分,适用于各类医疗模型应用的评估场景 | **平均值**:所有裁判员打分的总和除以裁判员数量。该数值反映打分的总体水平,但易受极端值影响,若存在过高或过低打分,平均值可能因极端值而失真。<br>**中位数**:将所有裁判员打分按大小排序后,位于中间位置的数值。若打分数量为偶数,则取中间两个数的平均值。该数值反映打分的集中趋势,不受极端值(过高或过低打分)影响,能较好体现裁判员打分的“中等水平”。<br>**标准差**:衡量裁判员打分相对于平均值的离散程度,即各打分与平均值之差的平方的平均数的平方根。该数值关注数据分布的离散程度,用于评估裁判员打分的稳定性和一致性,标准差越大,说明裁判员打分差异越大,一致性越低。 | ## 创建评估任务 在模型评估首页,点击创建自动评估,即可进入评估任务创建页面 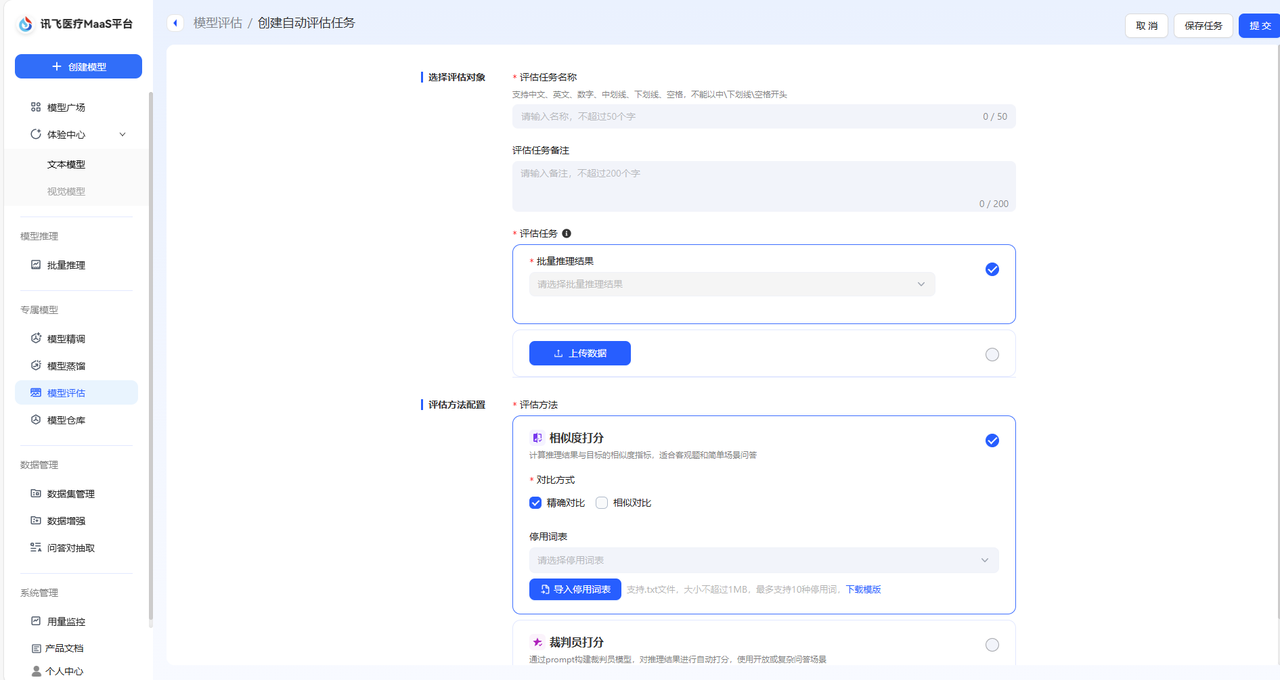 首先,您需要完成任务基本信息配置,包括配置评估任务对象、选填评估任务备注和选择评测集,评测集可以按照您自身的需求进行选择。 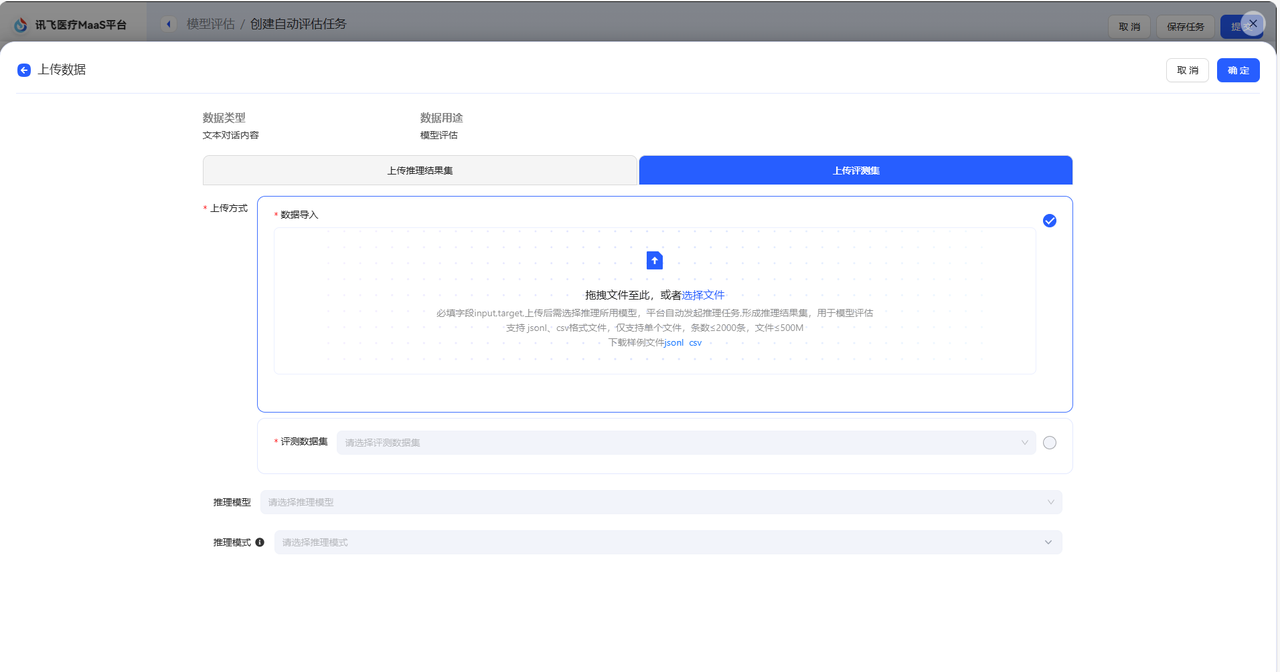 接着,需要选择评估方法,评估方法支持多选,您可以同时选择相似度打分和裁判员打分对模型进行评估。需要注意的是,若您选择裁判员打分,您可以对Metric和steps文本框中的内容进行修改。 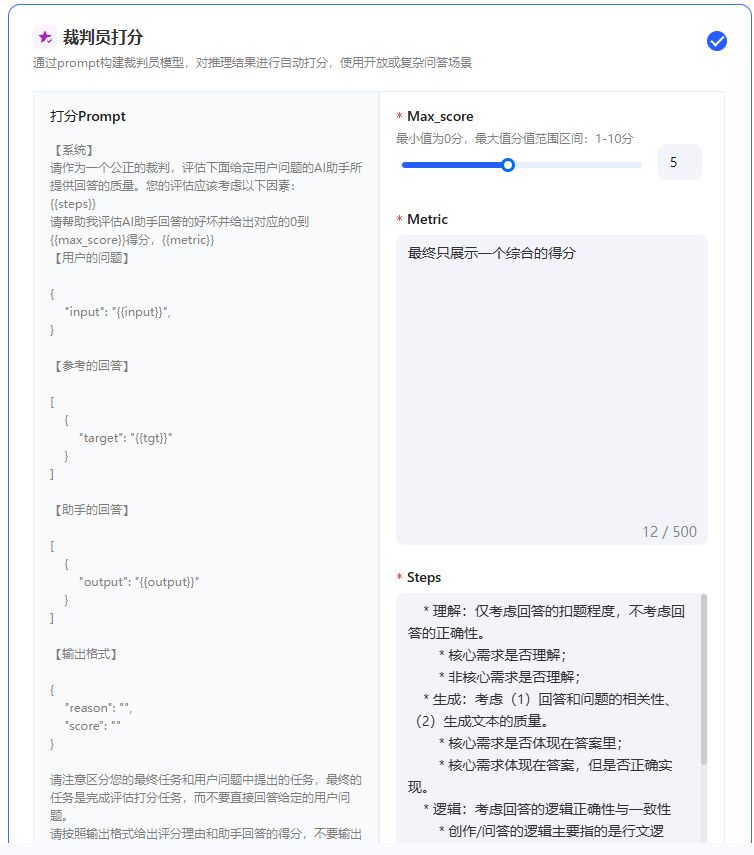 **Metric(评估指标)**:Metric 是用于量化模型性能的具体指标,若使用预置内容,则裁判员最终所展示的是各个指标的综合得分,可以与steps结合使用。 **steps(裁判评估维度)**:默认维度包括准确性、安全性、逻辑性、实用性和合规性五大维度,若您期望添加新的维度,可以根据默认维度的格式添加新维度。 最后,点击提交后即开始模型评估,评估后的结果可以在模型列表中点击查看评估报告,即可看到评估结果。 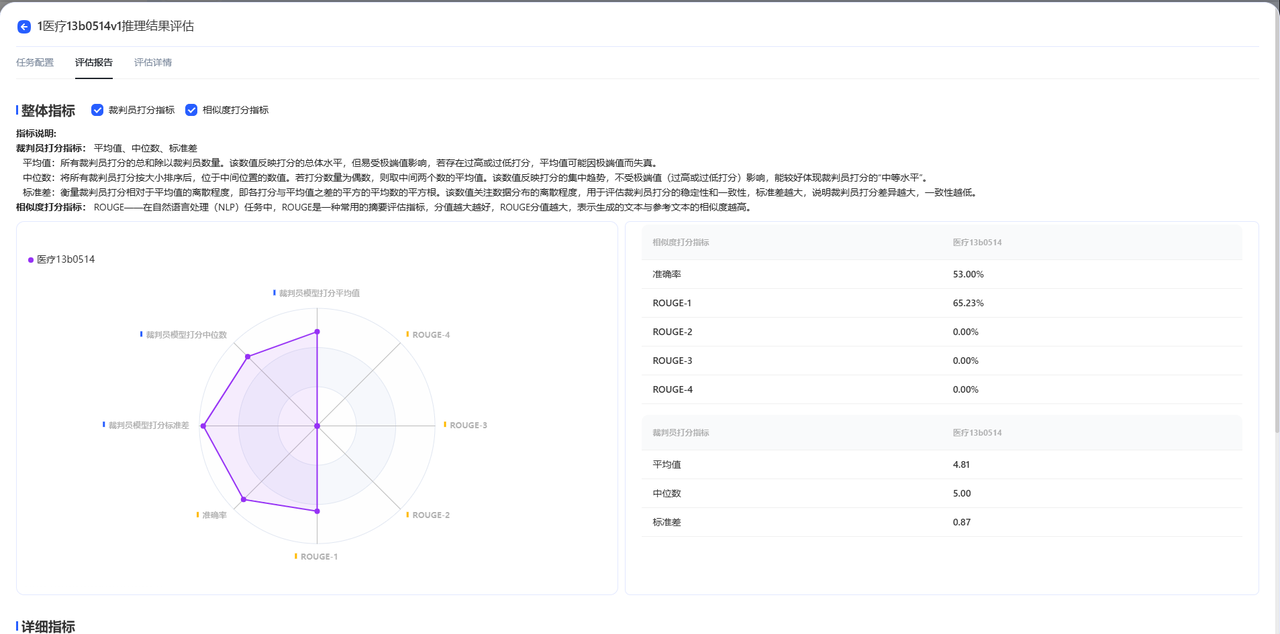
xuanwu2
2025年6月20日 16:07
转发文档
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
PDF文档(打印)
分享
链接
类型
密码
更新密码