讯飞医疗MaaS平台-模型精调平台
开始使用
平台简介
训练平台快速入门——功能速览
讯飞医疗MaaS平台-模型广场
讯飞医疗MaaS平台-数据管理
讯飞医疗MaaS平台-模型精调
讯飞医疗MaaS平台-批量推理
讯飞医疗MaaS平台-模型评估
讯飞医疗Maas平台-模型蒸馏
讯飞医疗MaaS平台-模型仓库
讯飞医疗MaaS平台-用量监控
模型能力
模型列表
模型能力
API参考
实践指南
功能详情
模型广场
数据管理
模型精调
批量推理
模型评估
模型蒸馏
模型仓库
用量监控
常见问题
相关协议
本文档使用 MrDoc 发布
-
+
首页
模型精调
通过模型精调您可以训练您的专属医疗领域模型应用,在选择需要训练的模型后,搭载专属训练集进行训练,精调后的模型可以成为您的专属医疗模型应用,满足您精确、安全与合规的医疗模型需求。 ## 模型精调数据集来源 模型精调仅支持使用训练集进行精调。平台不仅提供预置的医疗领域公开训练集,也支持用户自主创建训练数据集。 **医疗领域公开训练集**: 平台内置包括基础医学、西医临床医学、中医学、公共卫生与预防医学、心理医学、药物医学、护理医学、伦理医学、医学考试、医学技术和医学问答在内的11种医疗领域公开数据集。 在深入构建模型的全医学领域知识体系的同时,提升被精调模型的多任务处理能力,嵌入伦理知识、确保伦理合规与实践安全。预置数据集也根据不同的角色需求,对数据集进行分类,提升模型训练的准确度。 **自主创建训练集**: 您可以在创建精调任务时,自主创建训练集,在选择数据集类型时,选择类型为训练集即可。 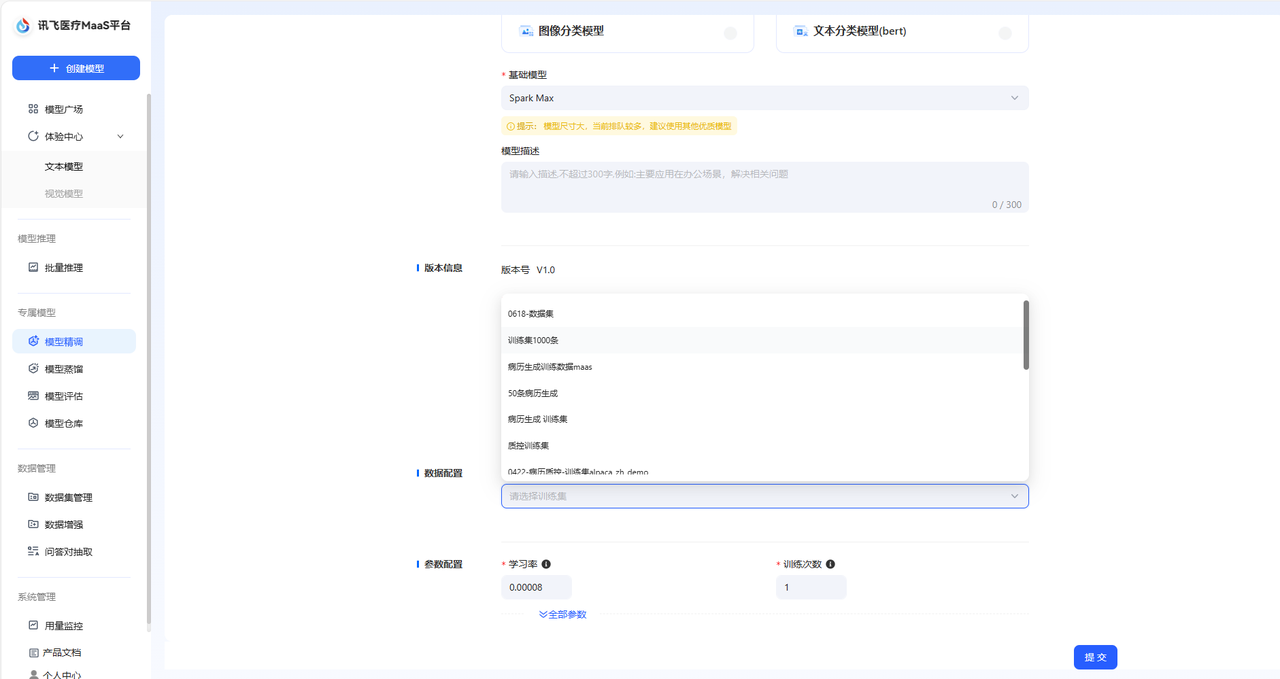 上述数据集均可在数据集管理页面对数据集进行管理。 **标注平台上传训练集**: 目前系统支持将在讯飞医疗MaaS-标注平台中标注后的训练集一键上传至训练平台,您可以直接在数据集管理页面中看到该数据集,通过打通标注平台与训练平台之间的数据集流转环节,能够全方位提高您的医疗工作效率,优化医疗服务。 ## 创建精调任务 点击导航栏中的模型精调后,即可进入模型精调的任务创建页面。 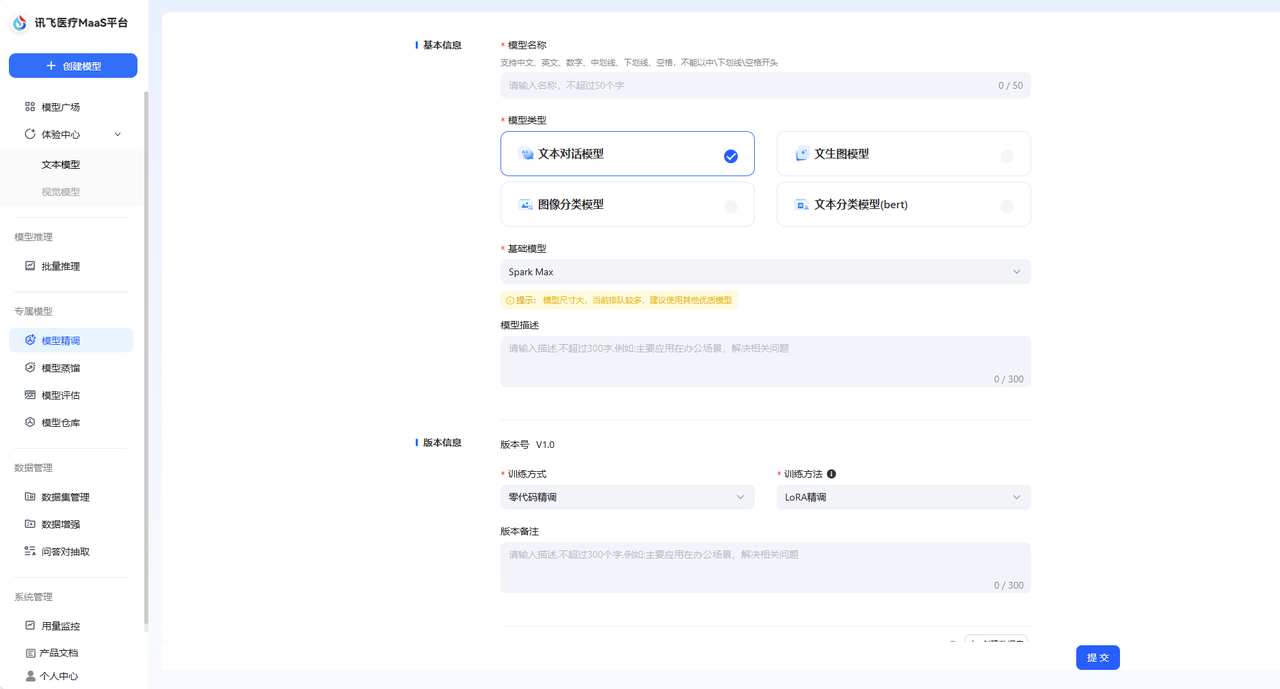 首先您需要配置任务的基本信息,包括填写模型名称、对于模型类型目前仅支持文本对话模型、选择基础模型以及选填模型描述。 其次,对于版本信息的配置,模型初次精调默认为V1.0版本,训练方式为零代码精调,训练方法为LoRA精调,均为默认。 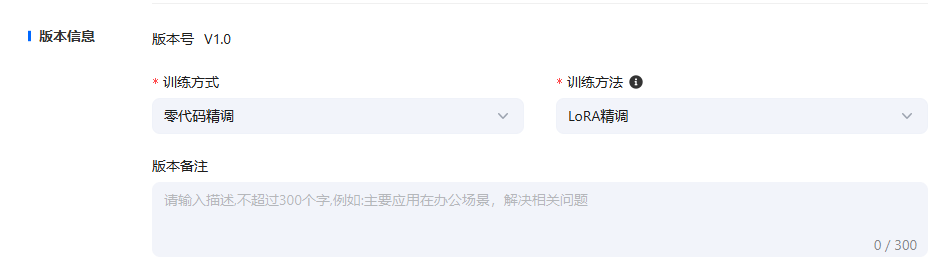 **注**: **零代码精调**:零代码精调是一种无需编写代码即可对模型进行训练的一种精调方式,通过可视化界面和参数配置工具,您可以直接参与模型的调整与优化。其核心在于将复杂的算法逻辑抽象为可操作的模块,满足您的核心医疗领域需求。 **LoRA精调**:LoRA是一种高效的模型微调技术,通过选择性地对预训练模型的部分参数进行低秩近似调整,在保持模型性能的同时大幅减少计算成本和显存占用。其核心思想是利用 “低秩分解” 简化模型参数的更新,避免对整个模型的数十亿参数进行全量训练。 接着,您需要选择训练集,训练集目前仅支持单选。参数配置为默认,支持修改。 完成后即可提交。精调后的模型,可以在模型仓库页面查看与管理。 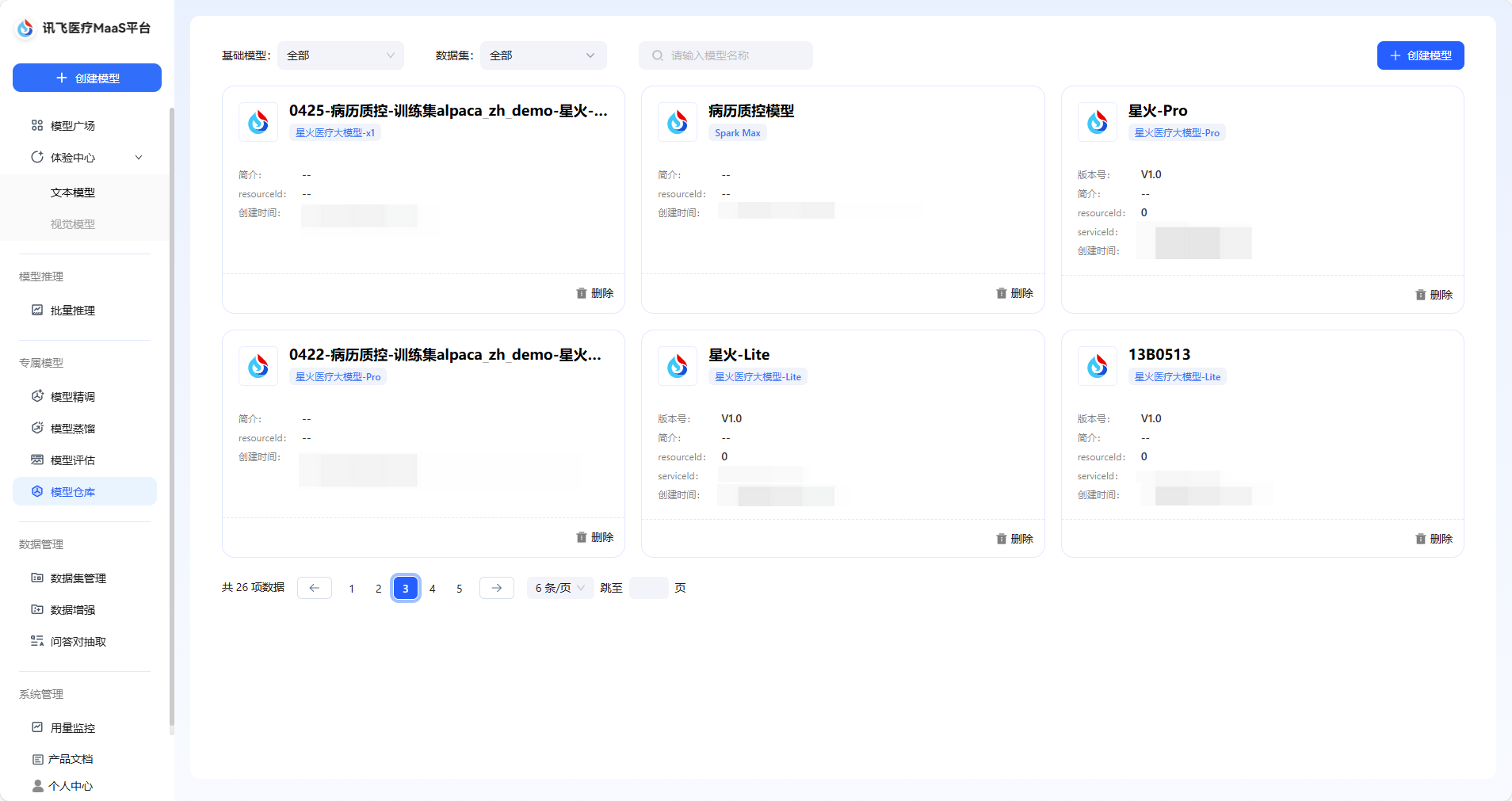 ## 参数配置说明 在配置精调任务时,您可以使用默认的参数配置,也支持对参数进行修改。参数说明如下: | 参数名称 | 定义 | 描述 | 默认参数值 | | ------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ | | 学习率 | 控制模型参数更新步长的速度。过高会导致模型难以收敛,过低则会导致模型收敛速度过慢。 | 学习率决定了模型在精调时的学习节奏,合适的学习率能够让预训练模型又快又准的进行训练,若学习率太高模型学习的结果会不够准确,若学习率太低模型的学习效率会较低。平台默认的学习率为系统推荐值。您也可以根据经验调整。 | 不同的模型支持不同的默认参数值,具体数值请参考您在实际操作过程中所查看的数值。 | | 训练次数 | 控制模型训练过程中遍历整个数据集的次数。建议设置在1-5之间,小数据集可增大Epoch以促进模型收敛。 | 训练次数是模型训练过程中学习全部训练集的次数,合适的训练次数能够使得模型高效准确的完成数据训练。 | | | 输入序列分词后的最大长度 | 单个训练数据样本的最大长度,超出配置长度将自动截断。超过该长度的数据在训练时将被舍弃,单位为token。较长的序列能够捕捉到更复杂的依赖关系,较短的序列可以提高计算效率。 | 在 LoRA 精调里,输入序列分词后的最大长度,就是模型能 一次性处理的最长句子(分词后的 token 数量)。比如模型最多能处理 8192个 “词块”(像中文里的字、词或英文的部分单词),超过这个数就会被截断或补零,即长句会被截断为短句进行处理。 | | | 数值精度 | 在深度学习和机器学习中,fp16(半精度浮点数)和 bf16(混合精度浮点数)是两种常见的数值精度表示方法。fp16 具有较高的精度,适合处理需要高精度但动态范围有限的任务; bf16 提供更广的动态范围和更好的数值稳定性,更适用于数值范围较大的任务,如深度学习中的大模型训练。 | 平台支持选择auto模式/fp16/bf16三种精度模式,若您选择默认的auto,那么系统会在精调过程中自动为您选择数值精度。数值精度指模型模型训练的精细程度,该精细程度可以用数值来进行量化,平台支持下述两种精度。fp16 是 “细节准但范围小”,适合需要精细小数的任务;bf16 是 “范围大但细节粗”,适合处理超大或超小的数字。 | | | lora作用模块 | 选择模型的全部或特定模块层进行微调优化 | **注意力模块**:该模块能够帮助模型在学习时对数据的主次部分进行认知,LoRA 作用后,能够使模型对重要部分认知更清晰。**前馈网络模块**:该模块能够帮助模型对信息进行加工,将信息变为模型能理解和使用的知识。LoRA 精调作用后能够帮助模型更高效的处理信息。通过作用这两个模块,LoRA 精调能够使得模型在语音理解和处理方面拥有更好的表现。 | | | LoRA秩 | 决定了微调过程中引入的低秩矩阵的复杂度。较小的秩可以减少参数数量,降低过拟合风险,但可能不足以捕捉任务所需的所有特征;较大的秩可能增强模型的表示能力,但会增加计算和存储负担。 | 系统支持的秩数值包括8和16两种。lora 秩指模型在学习时,要选一个合适的学习难度,让模型在效率和效果之间找到一个平衡。默认数值为8。 | | | Lora随机丟弃 | 用于防止Lora训练中的过拟合。 | Lora 随机丢弃指在模型训练过程中,随机地让模型 “忘记” 一些它正在学习的关于 LoRA 的参数细节。这样可以让模型不会过度依赖某些特定的参数,从而提高模型的适应能力和泛化能力。 | | | LoRA 缩放系数 | 定义了LORA适应的学习率缩放因子该参数过高,可能会导致模型的微调过度,失去原始模型的能力;改参数过低,可能达不到预期的微调效果。 | LoRA 缩放系数是模型进行精调时,用来控制模型学习新任务的速度和程度的一个参数,要根据实际情况选择合适的数值,让模型既能有效地学会新任务,又不会对原来的能力造成太大的负面影响。 | |
xuanwu2
2025年6月20日 15:50
转发文档
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
PDF文档(打印)
分享
链接
类型
密码
更新密码